Experiments were carried out in 10 anesthetized, tracheostomized, and spontaneously breathing adult cats of either sex. Sequential unilateral sections of phrenic nerve rootlets were performed yielding the experimental conditions of gradual partial or complete diaphragm paralysis on the ipsilateral side. The following six features were analyzed before (intact) and 1 hour after the phrenic nerve sectioning: breathing frequency (f), time of inspiration and expiration (TI, TE), tidal volume (VT), minute ventilation (VE=f x VT), and the amplitude of integrated phrenic nerve activity (AMPPHR). The study obtained approval of an institutional ethical committee.
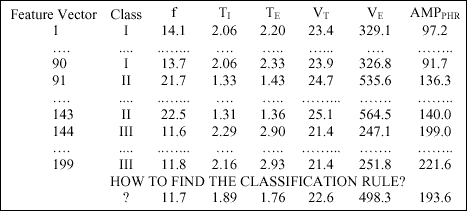
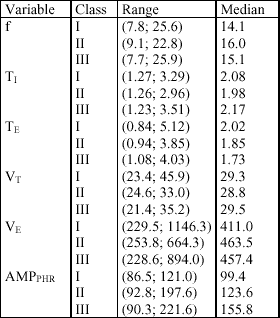
A data set of 199 measurements of the six features, representing breathing pattern, was obtained. The set contained 90, 53 and 56 feature vectors from the intact (Class I), partial (Class II), and complete (Class III) unilateral paralysis, respectively. It was called the training set or reference set and its form is shown in Table 1. The range of values and median for each variable analyzed are presented in Table 2.
| Table 1. The form of the analyzed data set - reference set. |
 |
| Table 2. Basic statistical description of variables in each class of the data matrix. |
 |
 |
| Fig. 1. The k-NN decision rule. |
Statistical methodology
We deal with the following question: is it possible to recognize the class of a measurement vector knowing the values of the vectors features? The probability of a correct recognition or misclassification would tell us how strong the relation between features and classes is. The pattern recognition theory estimates both the classification and misclassification rates. The most powerful classification rule is the standard k nearest neighbor rule (k-NN) (4). It assigns the classified case to the class most heavily represented from among its k most similar, i.e. nearest, samples in the reference set. The value of k ought to be estimated for the all possible values of k and k-NN rule in order to offer the lowest misclassification probability while classifying new cases.
There are two basic methods of experimental error rate estimation: the testing set method and the leave-one-out method. The former approach requires dividing of the data set into two parts: the training and the testing set. If the classifier derived from the training set classifies all m samples from the testing set and r of them are misclassified then the error rate, understood as ratio r/m, estimates the probability of misclassification. The latter approach allows using the whole data set as a training set. Each sample from the training set is classified by the rule derived from the training set decreased by the currently classified sample.
The leave-one-out method
The 1-NN rule, for the example presented in Fig. 2, during the course of the leave-one-out procedure, makes three misclassifications, since the nearest neighbors of points 4, 5 and 6 come from the opposite class. But the 3-NN rule misclassifies only points 5 and 6. This time the point 4 is correctly classified, since two out of its three nearest neighbors come from the same class. The 3-NN rule offers a minimum misclassification rate and this rule ought to be used to classified new samples.
| Fig. 2. One-dimensional example for the illustration of the leave-one-out method. |
The reference set reduction
Till now we have treated the terms the training set and the reference set as the synonyms. Strictly speaking the training set is the set that is used for the classifier construction while the reference set is the set, which must be stored in computer memory during the classification phase. It can be noticed, see Fig. 3, that it is sufficient to store only the points lying close to the class boundary. The reference set reduction algorithms have been developed only for the 1-NN rule (5).
 |
| Fig. 3. The Gowda-Krishna reference set reduction. |
The degree of dependence between classes and features
A minimum possible number of points in the reduced reference set is equal to the number nc of classes and cannot exceed the number m of points in the original reference set (the training set). The correlation approach, known from classical statistics, concerns a pair of variables, and the correlation coefficient (of any type) varies between 0 and 1. The reference set reduction algorithm can be used to introduce a similar dependence measure between classes and features. It can be defined as dm=(m-r)/(m-nc), where m is the numerical force of the training set, r is the size of the reduced reference set and nc denotes the number of classes. If r=m then dm=0, if r=nc then dm=1, since nc
The leave-one-out method enables the calculation of the number rij of points from class i assigned to class j. This number allows to compute the probability pij that a point from class i will be classified to class j and the probability qij that a point assigned to class i is in fact from class j: pij= rij/
| Table 3. Three types of matrices. |
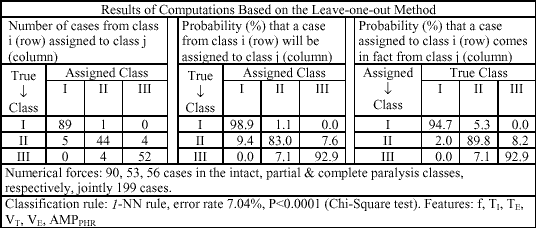 |
From among the 6 features, considered separately, the best is AMPPHR and the worst is VT (Table 4A). Adding sequentially next features in the best possible way, the best result, the error rate equal to 7.04%, offers the set of all 6 features (Table 4B). Subtraction of any single feature increases the misclassification rate (Table 4C). The feature AMPPHR is best, whether treated separately or in the context of the remaining features; its subtraction causes the error rate to increase from 7.04% to 13.07%. As a single feature, the worst is VT, but in the context of the 5 other features the worst becomes VE; its subtraction only slightly increases the error rate as compared with the set of all 6 features.
| Table 4. Results of feature selection. |
 |
The application of the Gowda-Krishna reference set reduction algorithm produces a reduced set containing only 47 points (out of 199) and then the dependence degree is equal to 0.78 (the counterpart of the correlation coefficient).
In conclusion, the statistical approach used can have a meaning for the development of diagnostic methods for diaphragm dysfunction, not only after the gradual unilateral paralysis of the muscle but also in other forms of impairment. To our opinion, the pattern recognition methods presented are powerful tools for statistical analysis of biomedical data and jointly with the classical statistics enable a better exploration of the knowledge contained in the data.
Acknowledgments: This work was supported by the statutory budget of the Polish Academy of Sciences Medical Research Center.
- Epstein SK. An overview of respiratory muscle function. Clin Chest Med 1994; 15: 619-639.
- Siafakas NM, Mitrouska I, Bouros D, Georgopoulos D. Surgery and the respiratory muscles. Thorax 1999; 54: 458-465.
- Rocco PR, Faffe DS, Feijoo M, Menezes SL, Vasconcellos FP, Zin WA. Effects of uni- and bilateral phrenicotomy on active and passive respiratory mechanics in rats. Respir Physiol 1997; 110: 9-18.
- Fix E, Hodges JL. Discriminatory Analysis: Nonparametric Discrimination Small Sample Performance. In NN Pattern Classification Techniques, BV Dasarathy (ed). IEEE Computer Society Press, Washington, DC, 1991, pp. 40-56.
- Gowda KC, Krishna G. The condensed nearest neighbor rule using the concept of mutual nearest neighborhood. IEEE Trans Information Theory 1979; 25: 488-490.